출처(기반으로 작성되었습니다): https://www.youtube.com/watch?v=w9GwqPx7LW8
1. 앞에서 배운 Q-Table 복습

2. Q-tabel 의 문제점 및 해결법

3. Q-Network = Q table을 Neural network 로 구현한것
network(Neural network) 는 입,출력이 조절가능한 네트워크임으로,
입력을 state만, 출력을 action으로 하여 설계할 것이다.

4. Q-Network 결론

5. Q-Network Training 과정
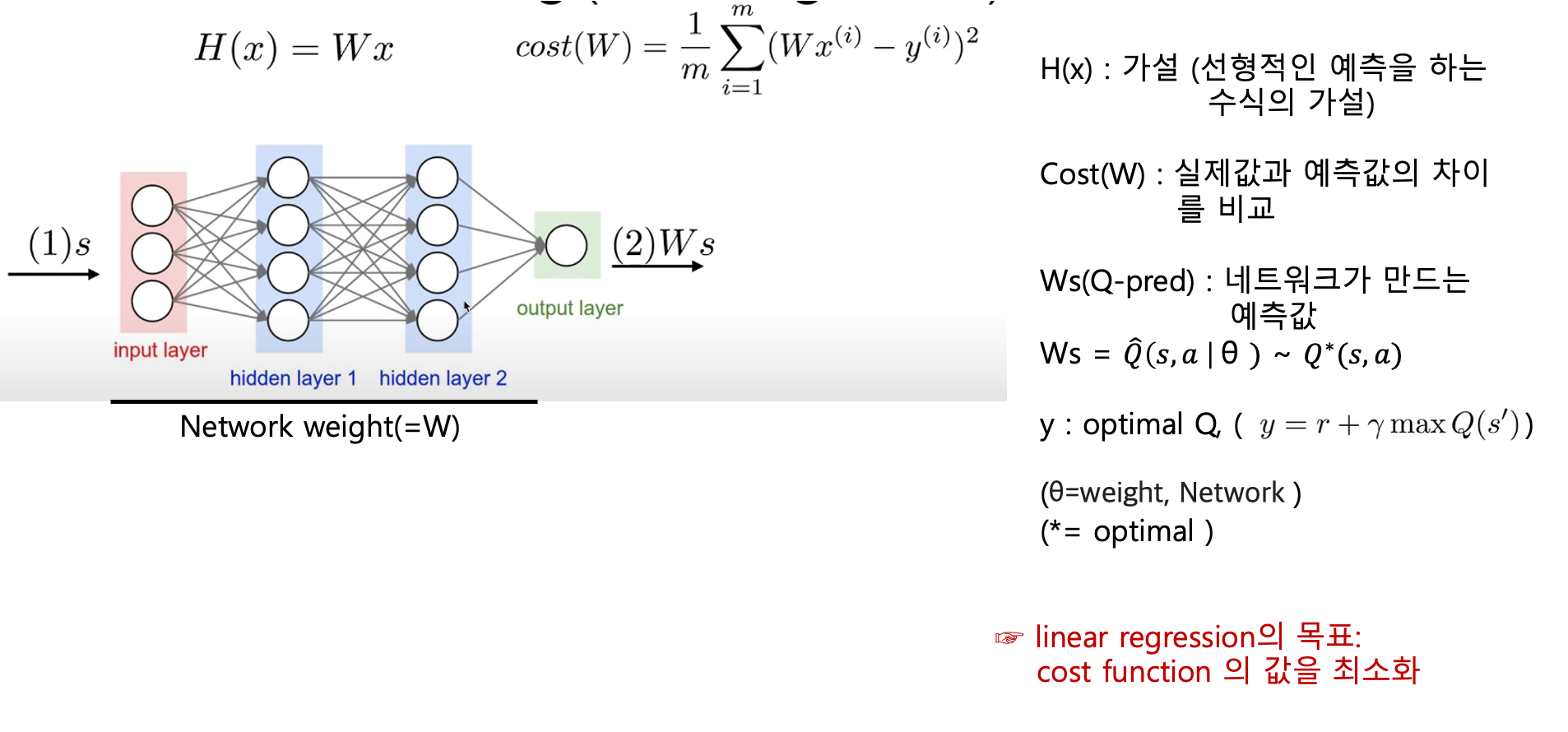
6. Q-Network 수학적 표기법

추가 설명 :
- Q*(s,a) : 최적 Q함수
- Q햇 (s,a | 세타 ) : 근사 Q함수 ( Q는 이상적인 Q함수를 의미함으로, Q에 근사한 값이기 에 Q햇 이라고 표현함)
7. Q-Network Algorithm

8. Stochastic 수식을 사용하지 않는 이유.
잘 생각을 해보면 앞장에서 Q 업데이트시 Stochastic 수식에 대해서 배웠는데,
이장에서 사용하는 수식을 보면 다르다는것을 알 수 있다. 그 이유는 아래 붉은 글씨로 표시해 두었다.

9. Network_for_Frozen_Lake 실습 코드
import gym
import numpy as np
import matplotlib.pyplot as plt
from gym.envs.registration import register
import random as pr
import os
import torch
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
###
### Network and setup
###
# 새로운 게임을 하나 만듬
register(
id='FrozenLake-v3',
entry_point='gym.envs.toy_text:FrozenLakeEnv',
kwargs={'map_name':'4x4','is_slippery':True}
)
env=gym.make("FrozenLake-v3") # 환경생성
#env=gym.make("FrozenLake-v3",render_mode='human') # 환경생성
input_size=env.observation_space.n # input shape = 16
output_size=env.action_space.n # output shape = 4
learning_rate=0.1
X=tf.placeholder(shape=[1,input_size],dtype=tf.float32) # (1 ,input_shape) 의 array 로 입력(x)(one-hot으로)을 주겠다.
W=tf.Variable(tf.random_uniform([input_size,output_size],0,0.01)) # 네트워크의 weight= 16*4 , 초기설정= 0 , 0.01
Qpred=tf.matmul(X,W) # 출력값을 구하는 방법은 X,W를 곱해서 구한다.(행렬곱셈 과정임))
Y=tf.placeholder(shape=[1,output_size],dtype=tf.float32) # Y label
loss = tf.reduce_sum(tf.square(Y - Qpred)) #loss 값이 설정.
train = tf.train.GradientDescentOptimizer(learning_rate
=learning_rate).minimize(loss) # learning_rate=학습률, loss값을 최소화 하는 방법으로 학습
dis= .99
num_episodes=2000
rList=[]
###
### Training
def one_hott(x):
return np.identity(16)[x:x+1]
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init) #초기화
for i in range(num_episodes):
s=env.reset() #method 임
s=s[0]
e=1./((i/50)+10)
rAll=0
done=False
local_loss=[]
#The Q-network training
while not done:
Qs=sess.run(Qpred,feed_dict={X:one_hott(s)})
if np.random.rand(1)<e: # e의 값보다 작으면 랜덤하게 갈꺼야
a=env.action_space.sample()
else:
a=np.argmax(Qs)
s1,reward,done,k,_=env.step(a)
## Y label, loss function 설정하는 부분.
if done:
Qs[0,a]=reward #reward도착시 reward 로 Q를 업데이트 함.
else:
Qs1=sess.run(Qpred,feed_dict={X:one_hott(s1)}) # 중간과정에 있다면 업데이트 해주는 부분.
Qs[0,a]=reward+dis*np.max(Qs1)
sess.run(train,feed_dict={X:one_hott(s),Y:Qs}) # X,Y를 동시에 넘겨주면서 -> 업데이트 된 Qs 값을 새롭게 학습해라.
rAll+=reward
s=s1
rList.append(rAll)
print("Sucess rate: "+str(sum(rList)/num_episodes))
plt.bar(range(len(rList)),rList,color='blue')
plt.show()(주의 tensorflow 버전을 낮춰야 함으로, 상단 부분 코드참고.)
9. Network_for_Frozen_Lake 실습 결과

10. Cartpole 실습 코드
import numpy as np
import tensorflow as tf
import gym
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
env=gym.make('CartPole-v1')
# 신경망 상수 설정.
learning_rate=1e-1
input_size=env.observation_space.shape[0] # input shape = 4
output_size=env.action_space.n # output shape = 2(좌,우)
X=tf.placeholder(tf.float32, shape=[None,input_size], name="input_x") #입력
# W1=tf.get_variable("W1",shape=[input_size,output_size],
# iniializer=tf.contrib.layers.xavier_initializer())
W1=tf.get_variable("W1",shape=[input_size,output_size],
initializer = tf.truncated_normal_initializer(stddev=0.1))
Qpred=tf.matmul(X,W1)
Y=tf.placeholder(shape= [None,output_size], dtype=tf.float32)
#loss function
loss = tf.reduce_sum(tf.square(Y - Qpred))
#learning
train = tf.train.AdamOptimizer(learning_rate
=learning_rate).minimize(loss)
num_episodes=2000
dis=0.9
rList=[]
init=tf.global_variables_initializer()
sess =tf.Session()
sess.run(init) #초기화
for i in range(num_episodes):
s=env.reset() #method 임
s=s[0]
e=1./((i/10)+1)
rAll=0
step_count=0
done=False
#The Q-network training
while not done:
step_count+=1
x=np.reshape(s,[1, input_size])
Qs=sess.run(Qpred,feed_dict={X:x})
if np.random.rand(1)<e: # e의 값보다 작으면 랜덤하게 갈꺼야
a=env.action_space.sample()
else: # e 보다 크면 Qs값으로 갈꺼야
a=np.argmax(Qs)
s1,reward,done,k,_=env.step(a)
## Y label, loss function 설정하는 부분.
## Qs= label(target)
if done:
Qs[0,a]=-100 # 끝이나면(넘어지면) -100을 reward로 줌.(넘어지지말라고)
else:
x1=np.reshape(s1,[1,input_size])
Qs1=sess.run(Qpred,feed_dict={X:x1}) # 다음상태에서 취할수 있는 Q값을 network에서 가져옴.
Qs[0,a]=reward+dis*np.max(Qs1)
sess.run(train,feed_dict={X:x,Y:Qs}) # X,Y를 동시에 넘겨주면서 -> 업데이트 된 Qs 값을 새롭게 학습해라.
s=s1 # 상태 업데이트
rList.append(step_count)
print("Episode: {} step: {}".format(i,step_count))
if len(rList)>10 and np.mean(rList[-10:])>500:
break
# 잘되는지 확인
observation=env.reset()
observation=observation[0]
reward_sum=0
while True:
env.render()
x=np.reshape(observation,[1, input_size])
Qs=sess.run(Qpred,feed_dict={X:x}) #모든 action을 가져오고
a=np.argmax(Qs) # 그 중 가장 좋은거 취함.
observation,reward,done,_,_=env.step(a)
reward_sum+=reward
if done:
print("Total score {}".format(reward_sum))
break11. Cartpole 실습 결과

'인공지능 (강화학습) > 강화학습' 카테고리의 다른 글
| [1] 강화학습 기본 개념 정리 (0) | 2024.03.20 |
|---|---|
| [4] 강화학습 Windy Frozen Lake Nondeterministic world! (1) | 2023.02.07 |
| [3] 강화학습 Exploit&Exploration and discounted future reward (1) | 2023.02.04 |
| [2]강화학습 Dummy Q Learning (1) | 2023.01.20 |
| [1] 강화학습이란? (0) | 2023.01.17 |



