출처 및 참고: https://www.youtube.com/watch?v=MQ-3QScrFSI&ab_channel=SungKim
(기반으로 작성된 글입니다)
2장에서의 배운내용.
의미 : '현재의 Q값은 실행해서 얻어지는 reward+그다음 단계에서 얻어지는 가장큰 reward' 이다.
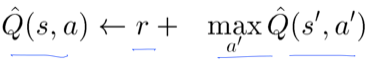

1. 기존의 문제점:
[2장]에서 Dummy Q learning 에 대해 배웠었는데 문제점이 존재한다.

정책(파이 옵티멀)에 의해 Q 값이 최대 가 되는 a(action)를 수행하며 나가는데 이것이 진짜 최적의 경로가 맞냐는 문제가 발생한다.
(계속 동일한 경로로만 가게됨)
2. 해결법:
이러한 비효율적인 동일한 경로로 가는것을 방지하기 위해 익숙한곳(Exploit) 과 새로운곳(Exploration) 을 가본다.
3. 방법(총 2개):
경로 탐색에 있어 노이즈(랜덤성)를 추가하는것이다. 가령 상,하,좌,우 중에 기존의 방식은 좌측만 갔더라면 3장에서는 좌측이 아닌 다른 경로로도 가보도록 노이즈를 임의로 추가함으로써 기존의 Q값을 새롭게 업데이트를 하는것이다.
3_1. 방법1.
명칭: E-greedy : 노이즈의 랜덤성을 부여함



예시 사진 fig1을 보게 되면 기존의 Q-value를 보게 되면 pizzahut(0.6)임으로 반복적인 학습시 동일한 경로로 목적지로 간다.
하지만 random_values를 추가함으로 popeyes의 Q-value가 1.0 이 됨으로 가장 큰 값이 됨을 확인할 수 있다. 그럼으로 popeyes 라는 action을 취하게 된다.
3_2. 방법2.
명칭: Decaying E-greedy : 후반부로 갈수록 랜덤한 노이즈의 가중치가 감소하면서 추가됨.


4. 노이즈 기법 특징:
기존의 값에 노이즈가 추가됨으로 2,3 번째의 좋은곳으로 갈 수 있게됨.(새로운 경로도 탐색하게 된다는 의미)
5. 알고리즘:

☞ Select an action a and excute it 이라는 의미가 Explot&Exploration 의 방법사용했다는 것이다.

6. 새로운 문제점 (Discounted future reward):

만약 Q-value의 값이 동일하다면 저 상태에서는(빨강색원) agent는 어떠한 action을 취해야할까?
이러한 문제를 방지하고자 등장한 해결책이 Discounted future reward 이다.
말그대로 번역을 하면 '미래의 보상에 대해 감소시킨다' 는 것이다.
(우리도 월급을 월급일날 받는게 좋지 몇일 뒤에 받으면 기분이 안좋지 않을까?)
7. 새로운 문제점 해결법
감마를 곱함으로 후반부의 가중치를 줄인다.( 0<감마<1)
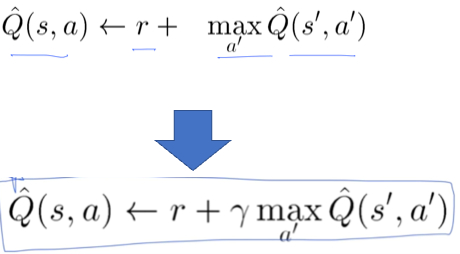
위와 같은 기존의 수식에서 감마(Γ)를 추가함으로써 미래에 받아지는 reward의 가중치를 약하게 둔다
7_1. Q-table 예시

추가설명 : D = B, C를 타고오는것임. 즉. 0(rewarid)+0.9(discount factor)*0.81(C의 값) =0.729 임.
8. 예제 코드 (noise 와 discounted reward 추가)
import gym
import numpy as np
import matplotlib.pyplot as plt
from gym.envs.registration import register
import random as pr
# 새로운 게임을 하나 만듬
register(
id='FrozenLake-v3',
entry_point='gym.envs.toy_text:FrozenLakeEnv',
kwargs={'map_name':'4x4','is_slippery':False}
)
env=gym.make("FrozenLake-v3",render_mode='human') # 환경생성
## 학습시키는 과정
Q=np.zeros([env.observation_space.n,env.action_space.n]) # Q 라는 테이블을 만든다.
num_episodes=2000 #반복횟수
dis=0.99 #discoumt factor
rList=[] #2000번 동안 성공횟수
for i in range(num_episodes):
state=env.reset()
state = state[0]
rALL=0
done=False
while not done:
action =np.argmax(Q[state, : ] +np.random.randn(1,env.action_space.n)/(i+1))
new_state,reward,done,_,_=env.step(action)
Q[state,action]=reward+ dis * np.max(Q[new_state,:])
rALL+=reward
state=new_state
rList.append(rALL)
##결과 출력
print("Sucess rate: "+str(sum(rList)/num_episodes))
print("Final Q-Table Values")
print(Q)
plt.bar(range(len(rList)),rList,color='blue')
plt.show()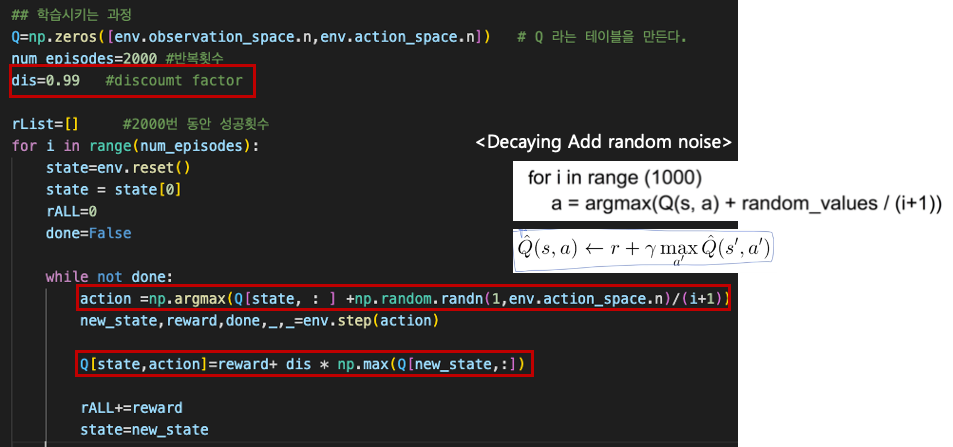
빨강색 박스를 친 부분이 기존의 코드에서 수정된 부분이다.
'인공지능 (강화학습) > 강화학습' 카테고리의 다른 글
| [1] 강화학습 기본 개념 정리 (0) | 2024.03.20 |
|---|---|
| [5] 강화학습 Q-Network (0) | 2023.02.15 |
| [4] 강화학습 Windy Frozen Lake Nondeterministic world! (1) | 2023.02.07 |
| [2]강화학습 Dummy Q Learning (1) | 2023.01.20 |
| [1] 강화학습이란? (0) | 2023.01.17 |



