출처 및 참고: https://www.youtube.com/watch?v=6KSf-j4LL-c&ab_channel=SungKim
1. Nondeterminisitc (Stochastic) 의미: 일정하지않다, 랜덤으로 실행되는..

그림1 설명: 방향 설정을 하더래도 어느 방향으로 가는지가 일정하지 않은것이다.


그림2 설명:
Deterministic 의 경우 알맞은 명령어에 따라 알맞게 agent 가 이동한다.
반면
Stochastic의 경우 명령어에 따라 알맞게 agent가 이동하지 않는다.
2. 앞장의 수식에서 문제점

3.해결법



4. Q-learning algorithm

5.실습 (slippery=True)
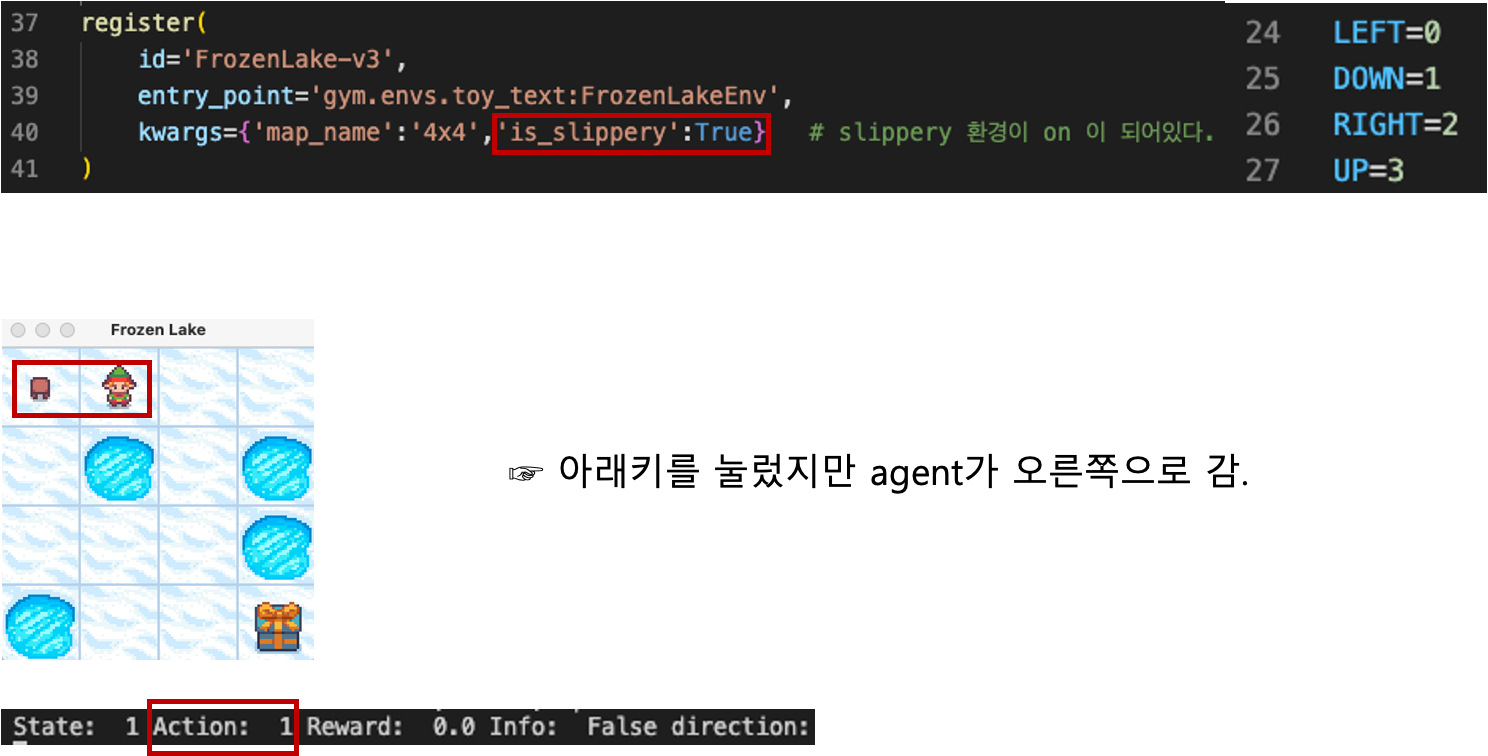

이번 장에서 수정된 식으로 하여 코드를 수정하였다.(그림3 참고)
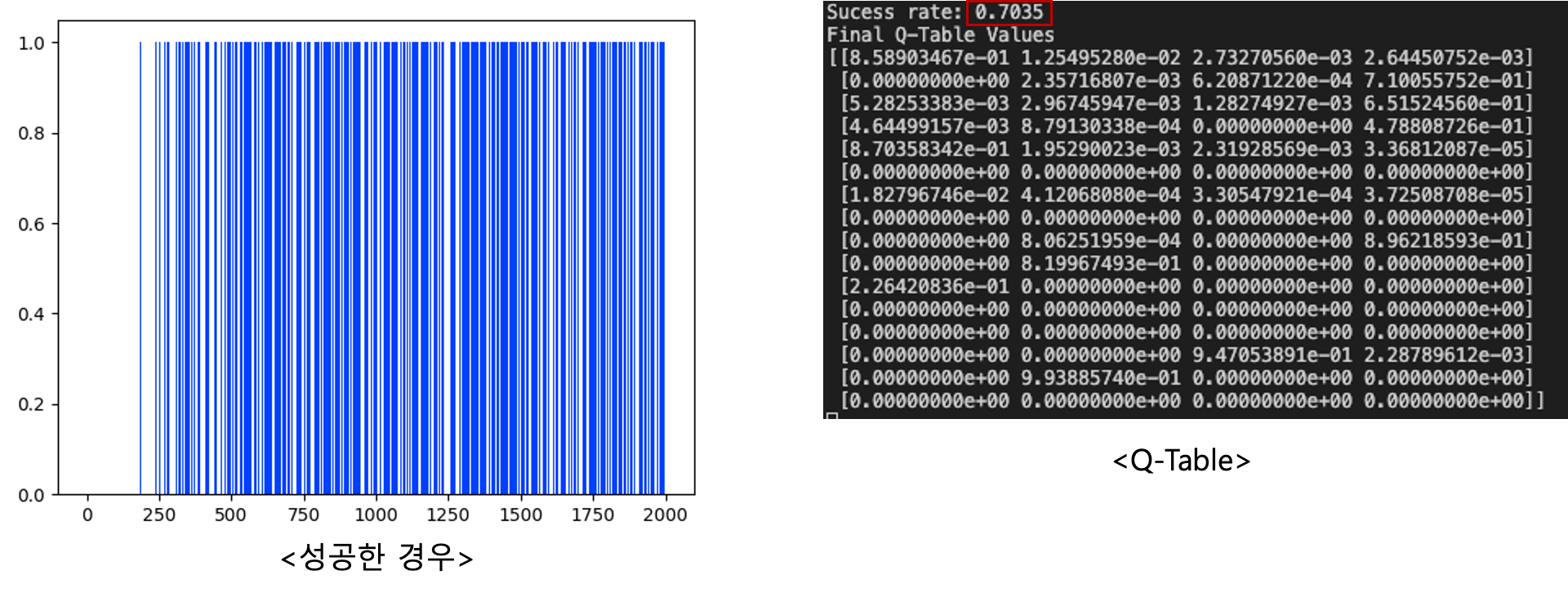
6. 실습 코드
import gym
import numpy as np
import matplotlib.pyplot as plt
from gym.envs.registration import register
import random as pr
# 새로운 게임을 하나 만듬
register(
id='FrozenLake-v3',
entry_point='gym.envs.toy_text:FrozenLakeEnv',
kwargs={'map_name':'4x4','is_slippery':True}
)
env=gym.make("FrozenLake-v3",render_mode='human') # 환경생성
## 학습시키는 과정
Q=np.zeros([env.observation_space.n,env.action_space.n]) # Q 라는 테이블을 만든다.
learning_rate=0.85 #크면 빨리학습, 작으면 천천히 학습
num_episodes=2000 #반복횟수
dis=0.99 #discoumt factor
rList=[] #2000번 동안 성공횟수
for i in range(num_episodes):
state=env.reset()
state = state[0]
rALL=0
done=False
while not done:
action =np.argmax(Q[state, : ] +np.random.randn(1,env.action_space.n)/(i+1))
new_state,reward,done,_,_=env.step(action)
Q[state,action]=(1-learning_rate)*Q[state,action] +learning_rate*(reward+ dis * np.max(Q[new_state,:]))
rALL+=reward
state=new_state
rList.append(rALL)
##결과 출력
print("Sucess rate: "+str(sum(rList)/num_episodes))
print("Final Q-Table Values")
print(Q)
plt.bar(range(len(rList)),rList,color='blue')
plt.show()'인공지능 (강화학습) > 강화학습' 카테고리의 다른 글
| [1] 강화학습 기본 개념 정리 (0) | 2024.03.20 |
|---|---|
| [5] 강화학습 Q-Network (0) | 2023.02.15 |
| [3] 강화학습 Exploit&Exploration and discounted future reward (1) | 2023.02.04 |
| [2]강화학습 Dummy Q Learning (1) | 2023.01.20 |
| [1] 강화학습이란? (0) | 2023.01.17 |



