소개 : 사람의 action 분류를 위해 Dataset을 통해 간단하게 코드를 작성하였다. 사람의 관절값을 추출하여 Human action recognition을 할 수 있지만, 여기서는 사람의 action자체를 이미지 분류 모델에 넣어서 분류 모델을 만듬.
코드 개요 : 모델을 만들기보다는 Finefuning을 수행함. , Early stopping 은 수행하지 않음.
난이도 : ★☆☆☆☆
주의: Kaggle Dataset에서 잘못된 파일명(?)이 있음, 그부분을 삭제해주고 시작해야함. ex)파일명뒤에 (1) 이렇게 붙어있음.
Dataset 출처 : https://www.kaggle.com/datasets/meetnagadia/human-action-recognition-har-dataset
Human Action Recognition (HAR) Dataset
The dataset features 15 different classes of Human Activities.
www.kaggle.com
1. 모듈 import
import torch.nn as nn
import torch
from torchvision.models import resnet50, ResNet50_Weights
import os
import pandas as pd
from torch.utils.data import Dataset
from sklearn.preprocessing import LabelEncoder
import torchvision.transforms as transforms
from PIL import Image
from torch.utils.data import DataLoader
from torch.utils.data import random_split
2. 모델 Finetuning 및 파라미터수 확인
class ResNet_Finetuning(nn.Module):
def __init__(self):
super().__init__()
resnet = resnet50(weights=ResNet50_Weights.IMAGENET1K_V2)
modules = list(resnet.children())[:-1] # delete last layer
self.resnet = nn.Sequential(*modules)
for param in self.resnet.parameters():
param.requires_grad = False
self.fc = nn.Sequential(
nn.Flatten(),
nn.BatchNorm1d(resnet.fc.in_features),
nn.Dropout(0.2),
nn.Linear(resnet.fc.in_features, 256),
nn.ReLU(),
nn.BatchNorm1d(256),
nn.Dropout(0.2),
nn.Linear(256, 15)
)
def forward(self, x):
x = self.resnet(x)
x = self.fc(x)
return x
resnet_finetuning = ResNet_Finetuning()
total_params = sum(p.numel() for p in resnet_finetuning.parameters())
print("Total Parameters:", total_params)
total_trainable_params = sum(p.numel() for p in resnet_finetuning.parameters() if p.requires_grad)
print("Total Trainable Parameters:", total_trainable_params)
total_fixed_params = sum(p.numel() for p in resnet_finetuning.parameters() if not p.requires_grad)
print("Total Fixed Parameters:", total_fixed_params)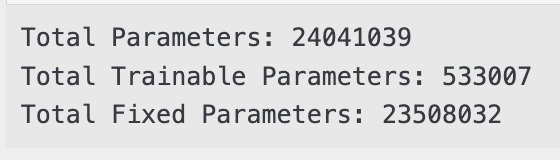
3. 커스텀 데이터셋 생성
주의 : 데이터셋의 label은 text(문자) 로 되어있음, 컴퓨터는 문자를 이해하지 못함으로 LabelEncoder 를 통해 숫자로 변환해야함.
class CustomDataset_name(Dataset):
def __init__(self, data_dir, csv_file, transform=None):
self.data_dir = data_dir
self.transform = transform
# 이미지 파일 리스트 생성
self.image_files = [f for f in os.listdir(data_dir) if os.path.isfile(os.path.join(data_dir, f))]
# CSV 파일 읽기
self.labels_df = pd.read_csv(csv_file)
# LabelEncoder를 사용하여 문자열 레이블을 숫자로 변환 및 encoded_label 컬럼 생성
self.label_encoder = LabelEncoder()
self.labels_df['encoded_label'] = self.label_encoder.fit_transform(self.labels_df['label'])
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_name = os.path.join(self.data_dir, self.image_files[idx])
image = Image.open(img_name)
if self.transform:
image = self.transform(image)
# Search label mapping with filename
label_row = self.labels_df[self.labels_df['filename'] == self.image_files[idx]]
label_num = label_row['encoded_label'].values[0]
label_str = label_row['label'].values[0]
# return image, label_num , label_str, img_name
return image, label_num
# 예제 사용
data_dir = './dataset/Human Action Recognition/train/' # 데이터가 저장된 디렉토리
csv_file = './dataset/Human Action Recognition/Training_set.csv'
# transform = transforms.Compose([
# transforms.Resize((224, 224)),
# transforms.ToTensor()
# ])
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Resize((224,224), antialias=True),
transforms.RandomHorizontalFlip(p=0.5),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
4. Train , Validation 분할.
trainset=CustomDataset_name(data_dir, csv_file, transform)
val_size = int(len(trainset) * 0.2)
train_size = len(trainset) - val_size
trainset, valset = random_split(trainset, [train_size, val_size])
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=1)
valloader = torch.utils.data.DataLoader(valset, batch_size=128, shuffle=False, num_workers=1)(기타) feature (이미지) , label (class) 의 데이터가 잘 묶여있는지 확인하는 코드
코드필요이유 : 코드를 작성하다보면 feature(이미지) 와 label (class) 을 작성자가 매핑을 해줘야 하는 경우가 생김. 이를 위해 아래와 같은 코드를 통해 알맞게 매핑이 되어있는지 확인.
기타 : 이를 실행하기 위해서는 'Customdataset_name' class 의 주석처리되어 있는 # return image, label_num , label_str, img_name 을 풀고하면 됨.
# import matplotlib.pyplot as plt
# import numpy as np
# import torchvision
# # 이미지를 보여주기 위한 함수
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
# dataiter = iter(trainloader)
# images, labels,label_str,img_name = next(dataiter)
# # 이미지 보여주기
# imshow(torchvision.utils.make_grid(images))
# # 정답(label) 출력
# print('label_str',label_str)
# print('img_name',img_name)
# print('labels : ',labels)
# classes = ('calling', 'clapping', 'cycling', 'dancing',
# 'drinking', 'eating', 'fighting', 'hugging', 'laughing', 'listening_to_music','running','sitting','sleeping','texting','using_laptop')
# print(' '.join(f'{classes[labels[j]]:5s}' for j in range(1)))
5. 하이퍼 파라미터 설정 및 Train 함수 정의.
lr=0.0001
epochs=50
criterion = nn.CrossEntropyLoss() # loss 함수
optimizer = torch.optim.Adam(resnet_finetuning.parameters(), lr=lr) # optimizer
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
resnet_finetuning=resnet_finetuning.to(device)
def train(model,train_loader,optimizer,log_interval):
# train 으로 설정. \
model.to(device)
for batch_idx,(image,label) in enumerate(train_loader):
image=image.to(device)
label=label.to(device)
# 그라디언트 0으로 초기화
optimizer.zero_grad()
output=model(image)
# print('output : ',output.size())
# print('label : ',label.size())
loss=criterion(output,label)
loss.backward()
# 파라미터 업데이트 코드.
optimizer.step()
if batch_idx %log_interval ==0:
# print('batch_idx',batch_idx)
# print('train_loader',len(train_loader))
print("Train Epoch: {}[{}/{}({:.0f}%)]\t Train Loss : {:.6f}".format
(epochs,batch_idx*len(image),len(train_loader.dataset),100*batch_idx/len(train_loader),
loss.item()))
def evaluate(model,test_loader):
#평가로 설정.
model.eval()
test_loss=0
correct=0
# 자동으로 gradient 트래킹 안함.
with torch.no_grad():
for batch_idx,(image,label) in enumerate(test_loader):
image=image.to(device)
label=label.to(device)
output=model(image)
test_loss+=criterion(output,label).item()
prediction=output.max(1,keepdim=True)[1]
correct+=prediction.eq(label.view_as(prediction)).sum().item()
test_loss /=len(test_loader.dataset)
test_accuracy=100.* correct/len(test_loader.dataset)
return test_loss,test_accuracy
6. Train 수행.
os.makedirs('./pt', exist_ok=True)
best_val_loss = float('inf') # Initialize with a large value to ensure the first validation loss will be lower
for epoch in range(1,epochs+1):
train(resnet_finetuning,trainloader,optimizer,log_interval=5)
test_loss,test_accuracy=evaluate(resnet_finetuning,valloader)
print("\n[Epoch: {}],\t Test Loss : {:.4f},\tTest Accuracy :{:.2f} % \n".format
(epoch, test_loss,test_accuracy))
if test_loss < best_val_loss:
best_val_loss = test_loss
# Save the model when the validation loss improves
model_path = f"{'./pt/'}model_epoch_{epoch}_Accuracy_{test_accuracy:.2f}.pt"
torch.save(resnet_finetuning.state_dict(), model_path)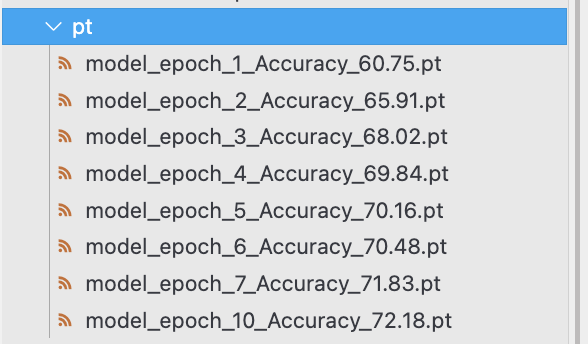
6. Inference 수행.
- 모델을 통째로 저장한것이 아닌 state_dict()를 저장했기 때문에, 모델의 아키텍쳐를 다시 불러와야함.
( 필자는 일반적으로 model폴더에 넣어두고 class를 import하는 방식으로 코드를 작성함, 여기서는 쉬운 이해를 위해 그냥 하나의 파일에서 작성 해서 함.)
import torch.nn as nn
import torch
from torchvision.models import resnet50, ResNet50_Weights
class ResNet_Finetuning(nn.Module):
def __init__(self):
super().__init__()
resnet = resnet50(weights=ResNet50_Weights.IMAGENET1K_V2)
modules = list(resnet.children())[:-1] # delete last layer
self.resnet = nn.Sequential(*modules)
for param in self.resnet.parameters():
param.requires_grad = False
self.fc = nn.Sequential(
nn.Flatten(),
nn.BatchNorm1d(resnet.fc.in_features),
nn.Dropout(0.2),
nn.Linear(resnet.fc.in_features, 256),
nn.ReLU(),
nn.BatchNorm1d(256),
nn.Dropout(0.2),
nn.Linear(256, 15)
)
def forward(self, x):
x = self.resnet(x)
x = self.fc(x)
return x
model_path='./pt/model_epoch_10_Accuracy_72.18.pt'
resnet_finetuning = ResNet_Finetuning()
resnet_finetuning.load_state_dict(torch.load(model_path))
resnet_finetuning.eval()
7. Label 생성을 위해불러옴.
추가설명 : 앞선 5번 과정까지 하나의 파일에서 연속해서 수행시키면 사실 아래의 코드는 필요없다, 하지만 Inference code를 다른 파일에 작성중이라면 Label의 정보가 없기 때문에 자명하게 필요한 과정이다.
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# CSV 파일 읽기
csv_file= './dataset/Human Action Recognition/Training_set.csv'
labels_df = pd.read_csv(csv_file)
# LabelEncoder를 사용하여 문자열 레이블을 숫자로 변환 및 encoded_label 컬럼 생성
label_encoder = LabelEncoder()
labels_df['encoded_label'] = label_encoder.fit_transform(labels_df['label'])
8. 이미지 출력 및 예측한 값 출력.
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from PIL import Image
from sklearn.preprocessing import LabelEncoder
test_path='./test_9_crop_1.jpg'
# test_path='./dataset/Human Action Recognition/train/Image_5.jpg'
# 이미지 입력을 위한 전처리
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Resize((224,224), antialias=True),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
image=Image.open(test_path).convert("RGB")
plt.imshow(image)
image = transform(image).unsqueeze(0)
print('Resized Image size : ',image.size())
predict_label=resnet_finetuning(image).argmax().item()
print('Predict label num : ',predict_label)
label_encoder.inverse_transform([predict_label])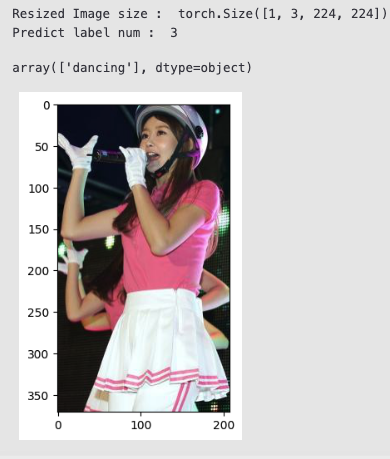
추가 : 원하는 부분의 이해가 잘 되지 않는다면 아래의 스크래치 코드를 보면 설명이 되어있음.
'인공지능/딥러닝 스크래치 코드' 카테고리의 글 목록
put-idea.tistory.com
'인공지능 (Deep Learning) > 딥러닝 사이드 Project' 카테고리의 다른 글
| [Image Captioning] 이미지 캡셔닝 튜토리얼 (0) | 2024.05.19 |
|---|---|
| [DETR Fine Tuning] DETR 모델을 활용한 Object detection (2) | 2024.04.25 |
| [MediaPipe] Gesture Recognition 을 이용한 모션인식 (8) | 2023.11.18 |
| [ViT] 비전 트랜스포머 코드구현 및 실행. (0) | 2023.08.11 |
| AutoFormer 코드 설명 및 적용. (0) | 2023.07.16 |



