논문: https://arxiv.org/abs/2010.11929
참고 깃허브: https://github.com/FrancescoSaverioZuppichini/ViT/tree/main
필자 깃허브( 코드 다운) : https://github.com/YongTaeIn/ViT
❏ 아래의 ppt와 같은 구조로 모델이 수행된다.
➢사실상 Transformer모델을 간파하고 있다면 초기의 input에서 patch로 변환하는것 이외에는 색다른 부분이 없다.

➢ Patching +CLS Token+ embedding


# patch embedding
# Add CLS Token
# position embedding
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch import nn
from torch import Tensor
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
from torchsummary import summary
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 224):
self.patch_size = patch_size
super().__init__()
# patch embedding
self.projection = nn.Sequential(
# using a conv layer instead of a linear one -> performance gains
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'),
)
# nn.Parameter = 학습 가능한 파라미터로 설정하는 것임.
# Add CLS Token
self.cls_token = nn.Parameter(torch.randn(1,1, emb_size))
# position embedding
self.positions = nn.Parameter(torch.randn((img_size // patch_size) **2 + 1, emb_size))
def forward(self, x: Tensor) -> Tensor:
b, _, _, _ = x.shape
x = self.projection(x)
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b) # cls token을 x의 첫번째 차원으로 반복함.
# prepend the cls token to the input
x = torch.cat([cls_tokens, x], dim=1) # torch.cat = concate -> cls_tokens 와 x 를 연결함. (= cls 토큰 추가 과정.)
# add position embedding
x += self.positions
return x➢ Make Transformer encoder


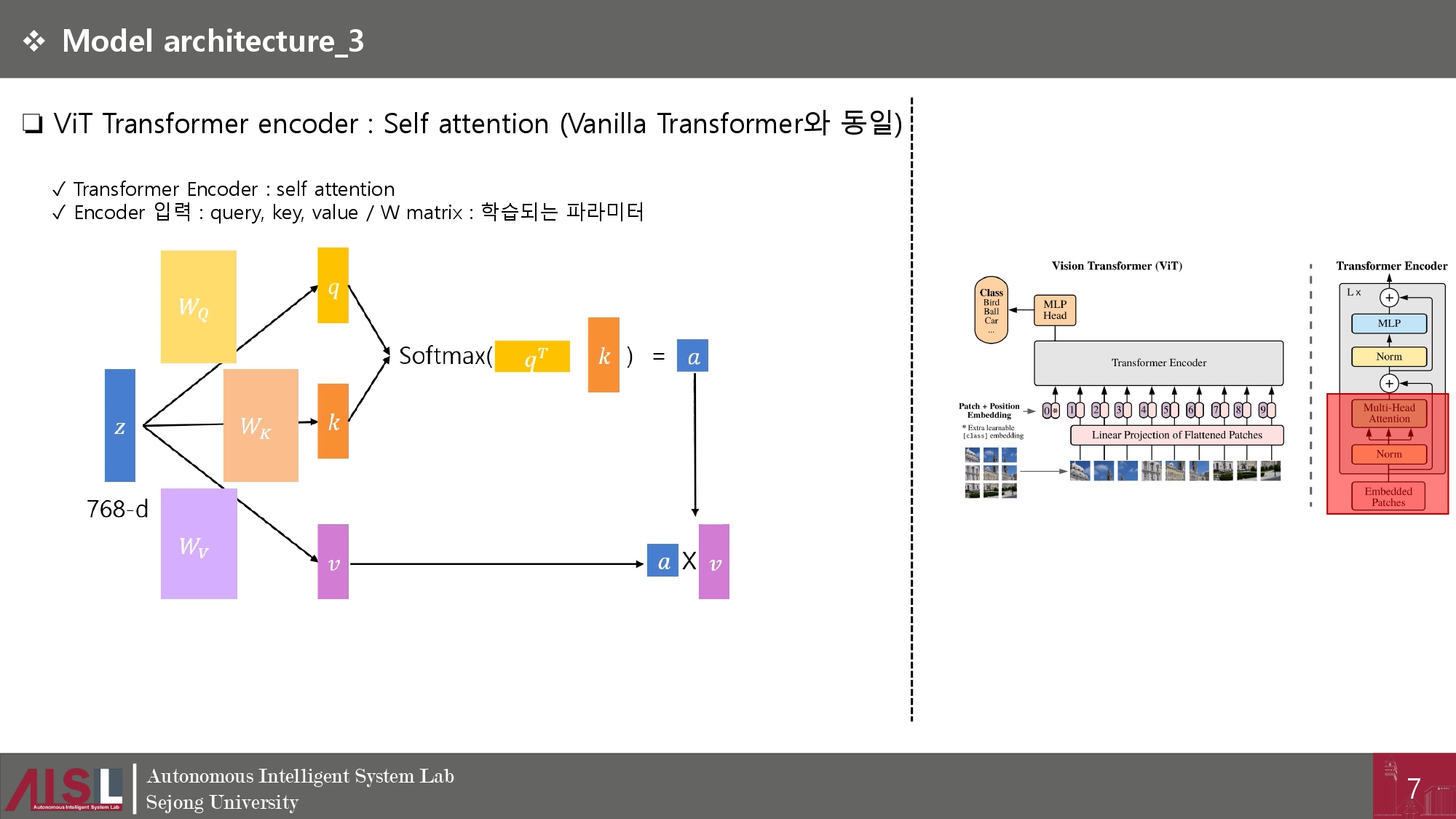


## Transformer encoder
##
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch import nn
from torch import Tensor
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
from torchsummary import summary
## Multihead attention.
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size: int = 768, num_heads: int = 8, dropout: float = 0):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
# fuse the queries, keys and values in one matrix
self.qkv = nn.Linear(emb_size, emb_size * 3)
self.att_drop = nn.Dropout(dropout)
self.projection = nn.Linear(emb_size, emb_size)
def forward(self, x : Tensor, mask: Tensor = None) -> Tensor:
# split keys, queries and values in num_heads
qkv = rearrange(self.qkv(x), "b n (h d qkv) -> (qkv) b h n d", h=self.num_heads, qkv=3)
queries, keys, values = qkv[0], qkv[1], qkv[2]
# sum up over the last axis
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys) # batch, num_heads, query_len, key_len
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
scaling = self.emb_size ** (1/2)
att = F.softmax(energy, dim=-1) / scaling
att = self.att_drop(att)
# sum up over the third axis
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
out = rearrange(out, "b h n d -> b n (h d)")
out = self.projection(out)
return out
# Residuals
#
class ResidualAdd(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
res = x
x = self.fn(x, **kwargs)
x += res
return x
# MLP layer
# 기타사항, nn.Sequential 임으로 굳이 def forward 쓸 필요가 없음.
#
class FeedForwardBlock(nn.Sequential):
def __init__(self, emb_size: int, expansion: int = 4, drop_p: float = 0.):
super().__init__(
nn.Linear(emb_size, expansion * emb_size),
nn.GELU(),
nn.Dropout(drop_p),
nn.Linear(expansion * emb_size, emb_size),
)➢ Encoder block을 원하는 개수로 쌓아주는 코드
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch import nn
from torch import Tensor
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
from torchsummary import summary
## load custom module
from layers.Multihead_attention import MultiHeadAttention, ResidualAdd, FeedForwardBlock
from layers.patch_embedding import PatchEmbedding
class TransformerEncoderBlock(nn.Sequential):
def __init__(self,
emb_size: int = 768,
drop_p: float = 0.,
forward_expansion: int = 4,
forward_drop_p: float = 0.,
** kwargs):
super().__init__(
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
MultiHeadAttention(emb_size, **kwargs),
nn.Dropout(drop_p)
)),
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
FeedForwardBlock(
emb_size, expansion=forward_expansion, drop_p=forward_drop_p),
nn.Dropout(drop_p)
)
))
class TransformerEncoder(nn.Sequential):
def __init__(self, depth: int = 12, **kwargs):
super().__init__(*[TransformerEncoderBlock(**kwargs) for _ in range(depth)])
➢ Make MLP Head

import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch import nn
from torch import Tensor
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
from torchsummary import summary
class ClassificationHead(nn.Sequential):
def __init__(self, emb_size: int = 768, n_classes: int = 1000):
super().__init__(
Reduce('b n e -> b e', reduction='mean'),
nn.LayerNorm(emb_size),
nn.Linear(emb_size, n_classes))❏ 학습 수행 코드. (CIFAR-10 사용)
위와 같이 각각의 역할을 하는 코드들을 다 만든 후에 train.py를 돌려준다.
## Load Module
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
import os
from torch import nn
from torch import Tensor
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
from torchsummary import summary
from torch.utils.data import random_split
# load custom module
from layers.patch_embedding import PatchEmbedding
from layers.Mlp_head import ClassificationHead
from layers.Earlystopping import EarlyStopping
from block.Encoder_Block import TransformerEncoder
# ## 알파(투명도) 채널 때문에 제거하려고 수행함.
# # 이미지를 열어서 알파 채널을 제거
from PIL import Image # RGBA (alpha 채널 제거 방법.)
# image = Image.open("./cat.png")
# image = image.convert("RGB")
# # 필요에 따라 이미지 크기를 변경 (ImageNet 크기로 변경하려면)
# image = image.resize((224, 224))
# # 이미지를 NumPy 배열로 변환 (옵셔널)
# image_array = np.array(image)
# # 이미지를 Pillow 이미지 객체로 변환 (옵셔널)
# image = Image.fromarray(image_array)
# # 알파 채널이 제거된 이미지를 저장하거나 처리에 사용
# image.save("./catt.png")
############# 모델
class ViT(nn.Sequential):
def __init__(self,
in_channels: int = 3,
patch_size: int = 16,
emb_size: int = 768,
img_size: int = 224,
depth: int = 12,
n_classes: int = 10,
**kwargs):
super().__init__(
PatchEmbedding(in_channels, patch_size, emb_size, img_size),
TransformerEncoder(depth, emb_size=emb_size, **kwargs),
ClassificationHead(emb_size, n_classes)
)
############# 모델
##############################################################
###################### CIFAR-10 데이터 다운 및 로드 ##############
##############################################################
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Resize((224,224), antialias=True),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
batch_size = 64
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
# 학습 데이터를 일정 비율로 나누어 validation set을 생성합니다
val_size = int(len(trainset) * 0.2) # 예시로 학습 데이터의 20%를 validation set으로 사용
train_size = len(trainset) - val_size
trainset, valset = random_split(trainset, [train_size, val_size])
# 데이터 로더를 생성합니다
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2)
valloader = torch.utils.data.DataLoader(valset, batch_size=batch_size, shuffle=False, num_workers=2)
## test loader
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
##############################################################
###################### train, valid 평가 함수. ##############
##############################################################
def train(model,train_loader,optimier,log_interval):
# train 으로 설정.
model.train()
for batch_idx,(image,label) in enumerate(train_loader):
image=image.to(device)
label=label.to(device)
# 그라디언트 0으로 초기화
optimizer.zero_grad()
output=model(image)
loss=criterion(output,label)
loss.backward()
# 파라미터 업데이트 코드.
optimizer.step()
if batch_idx %log_interval ==0:
print("Train Epoch: {}[{}/{}({:.0f}%)]\t Train Loss : {:.6f}".format
(epochs,batch_idx*len(image),len(train_loader.dataset),100*batch_idx/len(train_loader),
loss.item()))
def evaluate(model,test_loader):
#평가로 설정.
model.eval()
test_loss=0
correct=0
# 자동으로 gradient 트래킹 안함.
with torch.no_grad():
for batch_idx,(image,label) in enumerate(test_loader):
image=image.to(device)
label=label.to(device)
output=model(image)
test_loss+=criterion(output,label).item()
prediction=output.max(1,keepdim=True)[1]
correct+=prediction.eq(label.view_as(prediction)).sum().item()
test_loss /=len(test_loader.dataset)
test_accuracy=100.* correct/len(test_loader.dataset)
return test_loss,test_accuracy
##############################################################
###################### 모델 파라미터 설정. ##############
##############################################################
device = torch.device('cuda:2')
vit=ViT(in_channels = 3,
patch_size = 16,
emb_size = 768,
img_size= 224,
depth = 6,
n_classes = 10).to(device)
epochs=1000
lr=0.001
patience=10
early_stopping = EarlyStopping(patience = patience, verbose = True)
criterion = nn.CrossEntropyLoss() # loss 함수
optimizer = optim.SGD(vit.parameters(), lr=lr, momentum=0.9) # 최적화 함수.
os.makedirs('./pt', exist_ok=True)
best_val_loss = float('inf') # Initialize with a large value to ensure the first validation loss will be lower
for epoch in range(1,epochs+1):
train(vit,trainloader,optimizer,log_interval=5)
test_loss,test_accuracy=evaluate(vit,valloader)
print("\n[Epoch: {}],\t Test Loss : {:.4f},\tTest Accuracy :{:.2f} % \n".format
(epoch, test_loss,test_accuracy))
if test_loss < best_val_loss:
best_val_loss = test_loss
# Save the model when the validation loss improves
model_path = f"{'./pt/'}model_epoch_{epoch}_Accuracy_{test_accuracy:.2f}.pt"
torch.save(vit.state_dict(), model_path)
if early_stopping.early_stop:
print("Early stopping")
break➢ model evaluate 코드(evaluate.ipynb)
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Resize((224,224), antialias=True),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
batch_size = 64
## test loader
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# load custom module
from layers.patch_embedding import PatchEmbedding
from layers.Mlp_head import ClassificationHead
from layers.Earlystopping import EarlyStopping
from block.Encoder_Block import TransformerEncoder
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
import os
from torch import nn
from torch import Tensor
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
from torchsummary import summary
device = torch.device('cuda:1')
class ViT(nn.Sequential):
def __init__(self,
in_channels: int = 3,
patch_size: int = 16,
emb_size: int = 768,
img_size: int = 224,
depth: int = 12,
n_classes: int = 10,
**kwargs):
super().__init__(
PatchEmbedding(in_channels, patch_size, emb_size, img_size),
TransformerEncoder(depth, emb_size=emb_size, **kwargs),
ClassificationHead(emb_size, n_classes)
)
vit=ViT(in_channels = 3,
patch_size = 16,
emb_size = 768,
img_size= 224,
depth = 6,
n_classes = 10).to(device)
vit.load_state_dict(torch.load('./pt/model_epoch_126_Accuracy_66.68.pt'))
correct = 0
total = 0
# 학습 중이 아니므로, 출력에 대한 변화도를 계산할 필요가 없습니다
with torch.no_grad():
for data in testloader:
images, labels = data
images=images.to(device)
labels=labels.to(device)
# 신경망에 이미지를 통과시켜 출력을 계산합니다
outputs = vit(images)
# 가장 높은 값(energy)를 갖는 분류(class)를 정답으로 선택하겠습니다
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct // total} %')
# 각 분류(class)에 대한 예측값 계산을 위해 준비
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}
# 변화도는 여전히 필요하지 않습니다
with torch.no_grad():
for data in testloader:
images, labels = data
images=images.to(device)
labels=labels.to(device)
outputs = vit(images)
_, predictions = torch.max(outputs, 1)
# 각 분류별로 올바른 예측 수를 모읍니다
for label, prediction in zip(labels, predictions):
if label == prediction:
correct_pred[classes[label]] += 1
total_pred[classes[label]] += 1
# 각 분류별 정확도(accuracy)를 출력합니다
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print(f'Accuracy for class: {classname:5s} is {accuracy:.1f} %')

☞ Data augumentation 을 하지 않아 성능이 그렇게 좋지 않음을 확인 할 수 있다.
(무튼 Data augumentation 를 추가해서 한다면 성능이 좋아지겠지)
➢ 기타 코드 : Early stopping
import torch
import numpy as np
class EarlyStopping:
"""주어진 patience 이후로 validation loss가 개선되지 않으면 학습을 조기 중지"""
def __init__(self, patience=7, verbose=False, delta=0, path='checkpoint.pt'):
"""
Args:
patience (int): validation loss가 개선된 후 기다리는 기간
Default: 7
verbose (bool): True일 경우 각 validation loss의 개선 사항 메세지 출력
Default: False
delta (float): 개선되었다고 인정되는 monitered quantity의 최소 변화
Default: 0
path (str): checkpoint저장 경로
Default: 'checkpoint.pt'
"""
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
self.path = path
def __call__(self, val_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score < self.best_score + self.delta:
self.counter += 1
print(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 0
def save_checkpoint(self, val_loss, model):
'''validation loss가 감소하면 모델을 저장한다.'''
if self.verbose:
print(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')
torch.save(model.state_dict(), self.path)
self.val_loss_min = val_loss
early_stopping = EarlyStopping(patience = 20, verbose = True)
❏ 편하게 코드 다운을 하고 싶으면 github 에서 다운받으면 된다.
https://github.com/YongTaeIn/ViT
GitHub - YongTaeIn/ViT
Contribute to YongTaeIn/ViT development by creating an account on GitHub.
github.com
'인공지능 (Deep Learning) > 딥러닝 사이드 Project' 카테고리의 다른 글
| [DETR Fine Tuning] DETR 모델을 활용한 Object detection (2) | 2024.04.25 |
|---|---|
| [MediaPipe] Gesture Recognition 을 이용한 모션인식 (8) | 2023.11.18 |
| AutoFormer 코드 설명 및 적용. (0) | 2023.07.16 |
| [트랜스포머] 트랜스포머 인코더를 이용한 시계열 예측. (2) | 2023.07.13 |
| [CNN-Tensorflow] 커스텀 데이터 활용 이미지 분류 예제 코드 설명 (5) | 2023.02.26 |



