논문링크: https://arxiv.org/abs/2203.00555
DeepNet: Scaling Transformers to 1,000 Layers
In this paper, we propose a simple yet effective method to stabilize extremely deep Transformers. Specifically, we introduce a new normalization function (DeepNorm) to modify the residual connection in Transformer, accompanying with theoretically derived i
arxiv.org
논문링크: https://arxiv.org/abs/2210.06423
Foundation Transformers
A big convergence of model architectures across language, vision, speech, and multimodal is emerging. However, under the same name "Transformers", the above areas use different implementations for better performance, e.g., Post-LayerNorm for BERT, and Pre-
arxiv.org
Microsoft의 KOSMOS 논문을 이해하기 위해서는 DeepNet, Foundation Transformers 논문의 선행지식이 필요하다. 이를 위해 이번 번 리뷰에서는 필요한 각각의 논문에서 필요한 부분만 정리하려 한다.

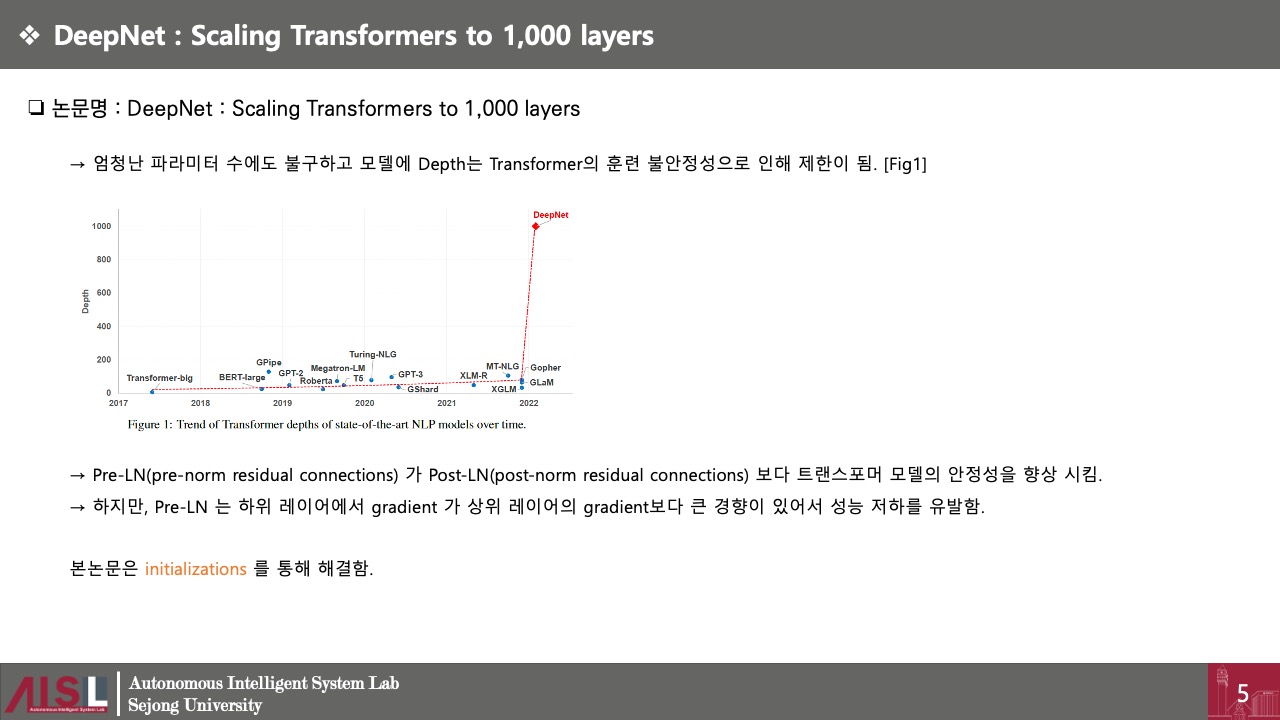

결국 DeepNet이라는 논문에서 하고 싶은 말은 encoder, decoder 블록의 수에 알맞게 α 와 β를 설정해서 사용한다는것이다.
여기서
α는 residual 과정에서 Input 에 대한 scaling이고
β는 xavier_noraml 의 파라미터인 gain값이다.



Foundatino Transformers 라는 논문에서 하고 싶은 말은 encoder, decoder 블록의 수에 알맞게 gain(Γ) 을 설정 한다는것이며
Layernorm을 attention layer 전후에 추가 한다는 것이다.



