- 새로 알게 된점 및 중요사항:
1. 시계열 데이터를 성능검증할때 sktime의 temporal_train_test_split 사용.
(시계열에서 이걸사용하는게 맞음. 순서 정보 유지해야 하니깐.)
= train_test_split( shuffle=False) 랑 동일 함. (시계열에서는 False 해야함)
2. seed 를 여러개로 설정후 반복해서 모델을 일반화 하여 평가함.
3. test_size를 0.0~1.0 의 float 형태로 할 수 있지만. 구체적인 int값으로 하여 설정가능.
int로 하면 test_size의(시계열 데이터에서 가장 최근데이터(마지막데이터)) 구체적인 값의 범위
설정가능
# 1번 확인을 위한 예시 코드
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.datasets import load_airline, load_osuleaf
from sktime.utils._testing.panel import _make_panel
from sklearn.model_selection import train_test_split
# univariate time series
y = load_airline()
print(y.shape) # (144,)
print(y) # 1949-01 112.0 ~ 1960-12 432.0
y_train, y_test = temporal_train_test_split(y, test_size=36)
y_train_1, y_test_1 = train_test_split(y, test_size=36, shuffle=False)
print('y_train',y_train.shape) # y_train (108,)
print('y_test',y_test.shape) # y_test (36,)
print('y_train_1',y_train_1.shape) # y_train_1 (108,)
print('y_test_1',y_test_1.shape) # y_test_1 (36,)
-느낀점:
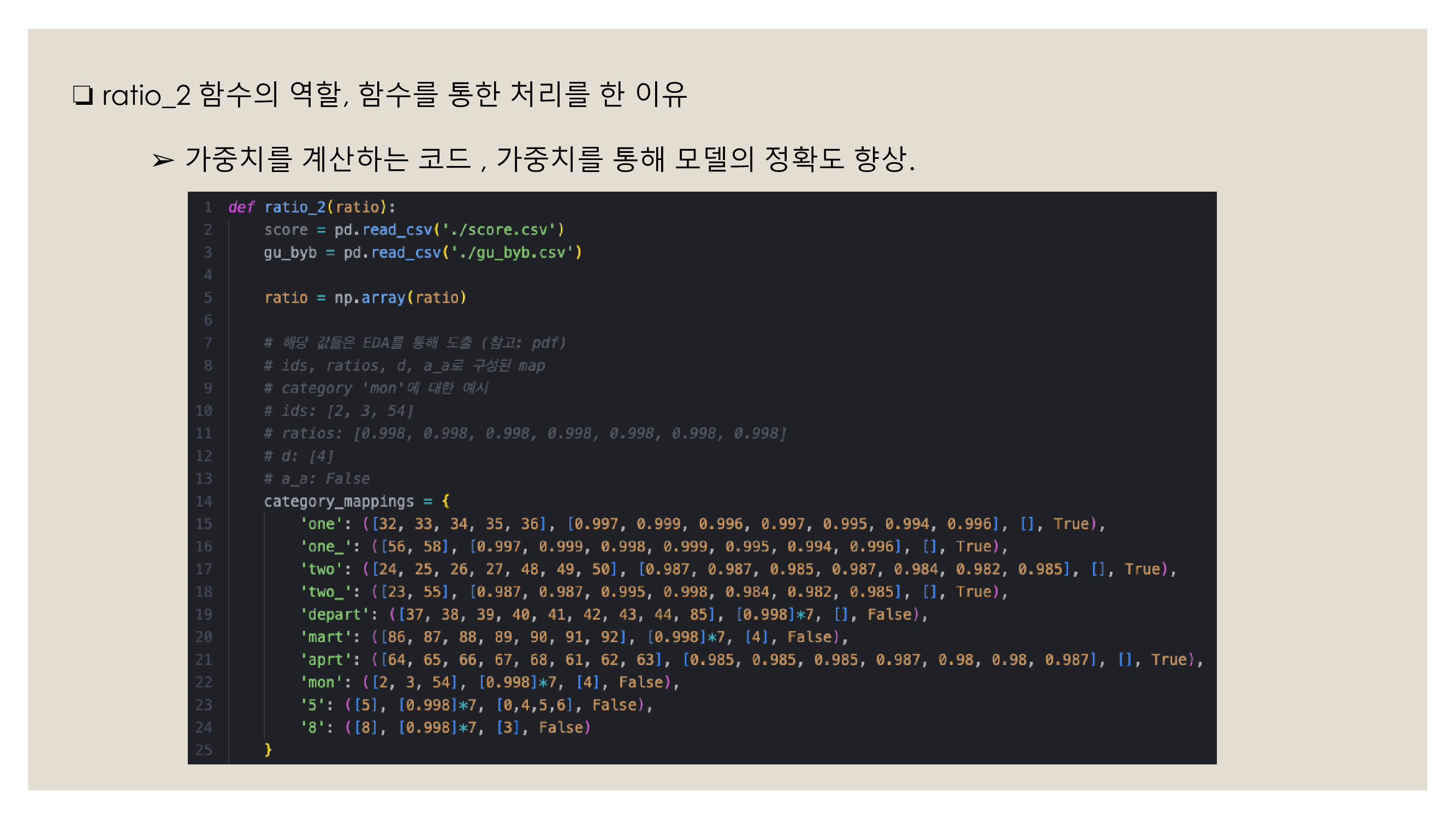
1. '정형' 문제에서는 모델을 힘들게 찾기보단 전처리가 상당히 중요한 과정이라는것을 알 수 있었다.
건물 하나하나 확인해서 ratio(가중치)를 설정하는 것부터. 건물별로 휴일(휴관일)이 있는것과 확인하는 등
전처리가 이정도일줄은 몰랐는데 중요도가 8(전처리):2(모델) 의 비율인것 같다.





'Study 공부 > 데이스쿨 (전력사용량(시계열) 우승자코드 분석)' 카테고리의 다른 글
| 데이스쿨 스터디 - 전력 사용량 예측 [2] (전처리) (0) | 2023.10.13 |
|---|---|
| 데이스쿨 스터디 - 전력 사용량 예측 [1] (0) | 2023.10.01 |

