들어가기 전에-> 1. CNN의 기본 개념은 타 블로그 글을 참고하면 될 거 같습니다.
2. 개념은 알지만 코드를 짜는 부분에 있어서 헷갈리는 분들을 위한 글입니다.
3. reshape 하는 방법이 메인이 되는 게시글입니다.
4. Conv1D 가 첫 번째 layer 인 예시입니다.
5. 주어진 데이터는 시계열 데이터 이지만 시계열 데이터가 아닌것 처럼
코드를 작성 하였습니다. (단순 회귀 예측 처럼 작성함)
1. Conv1D 와 Conv2D 차이
(Conv1D에 대한 글은 너무 없어서 공부할 때 힘들었다.. 거의 conv2d+이미지 처리..)

1. 1D에서 보면 9개의 예시가 있고 feature의 개수가 6개이다.
2. 한 방향으로만 커널(필터)이 움직인다. (가로축으로만 or세로축으로만) 여기서는 세로축으로 움직임.
3. 커널(필터)의 사이즈=Height이고 현재 그림에서 2이다.
(아래는 가로축으로 움직이는 커널(필터), Feature의 개수가 3개, 20개의 예시)
2. 맛보기, 예시를 통한 간단 설명
(아마 이 부분이 가장 헷갈리는 부분 아닐까 예상해봅니다.)
가공 전 데이터 : 404개의 예시 , 13개의 특징 -> (404,13)=(batch_size, feature개수)
tip) batch_size=sample_size
가공 후 데이터 : (404,13,1) =(batch_size, time_steps, input_dimension)
tip) input_dimension 은 1로 고정임. 특징 여러 개를 1차원으로 간주하기 때문.
tip) time_steps=feature개수
첫 번째 layer Conv1D 에 들어가는 input_shape= (13,1) =(time_steps, input_dimension)
3. 전체 코드
1. 모듈 import
import pandas as pd
import numpy as np
from keras.layers import Conv1D, GlobalMaxPooling1D,Dense, Dropout , MaxPooling1D ,LSTM,InputLayer,Flatten
from keras.models import Sequential
from keras.callbacks import EarlyStopping, ModelCheckpoint
from sklearn.model_selection import train_test_split 2. 엑셀 데이터 및 약간의 전처리 방법은 생략함. (랩실 과제이며 파일명 수정하고 등등의 이유..)
3. 불러온 데이터 모습. (feature 한 개입니다)
4. input데이터로 사용하기 위한 Train Data 3차원으로 만들기.
주의) feature, label 둘 다 3차원임.
tip) 추출한 feature의 개수가 a 개라면 reshape(-1, a)하면 됨.
# TRAIN DATA(학습데이터) 3차원 만드는 과정.
#현재 1차원임.
feature=np.array(DODI_C_20_5)[:,1] # DODI_C_20_5 의 feature를 뽑아냄.
label=np.array(DODI_C_20_5)[:,0] # DODI_C_20_5 의 label을 뽑아냄.
feature.shape , label.shape # -> (3732,), (3732,)
#2차원으로 만들어주기
feature=feature.reshape(-1,1) # reshape(-1,n) = n열에 맞춰서 알아서 행을 정해줌.
label=label.reshape(-1,1) # if) feature가 a개라면 reshape(-1,a)하면 됨.
feature.shape , label.shape # -> (3732, 1), (3732, 1)
#3차원으로 만들어주기
feature=feature.reshape(feature.shape[0],feature.shape[1],1)
label=label.reshape(label.shape[0],label.shape[1],1)
feature.shape , label.shape # -> (3732, 1, 1), (3732, 1, 1)5. 모델 평가를 하기 위한 Test Data 만들기.
-> data가공할때 들어가는 input=(sample_size,time_steps,1) =(batch_size, feature개수, 1)
주의) test_feature =3차원 , test_label =2차원
# TEST DATA(테스트 데이터) 차원 만드는 과정.
test_feature=np.array(DODI_C_20_6)[:,1] # DODI_C_20_6 의 feature를 뽑아냄.
test_label=np.array(DODI_C_20_6)[:,0] # DODI_C_20_6 의 label을 뽑아냄.
test_feature=test_feature.reshape(-1,1)
test_label=test_label.reshape(-1,1)
test_feature=test_feature.reshape(test_feature.shape[0],test_feature.shape[1],1)
#test_label=test_label.reshape(test_label.shape[0],test_label.shape[1],1)
test_feature.shape, test_label.shape # ->((3731, 1, 1), (3731, 1))6. Overfitting방지
## overfitting 방지
x_train, x_valid, y_train, y_valid = train_test_split(feature, label, test_size=0.2 , random_state=34)
x_train.shape , y_train.shape # -> (2985, 1, 1), (2985, 1, 1)7. 모델 설계
model=Sequential()
model.add(Conv1D(64,1,input_shape=(1,1),activation='relu'))
# 64= 필터(커널)개수 / 1= 필터(커널)의size = (행의 개수) /input shape =(feature 개수 ,1) , 그리고 data가공할때 들어가는 input.shape=(sample_size,time_steps,1)
# 필터하나당 하나의 result나옴
model.add(Dropout(0.5))
model.add(Conv1D(32,3,padding='same',activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Flatten()) # dense layer에 맞추기 위해. flatten사용
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5)) # drop out 50% 함
model.add(Dense(1))
model.summary()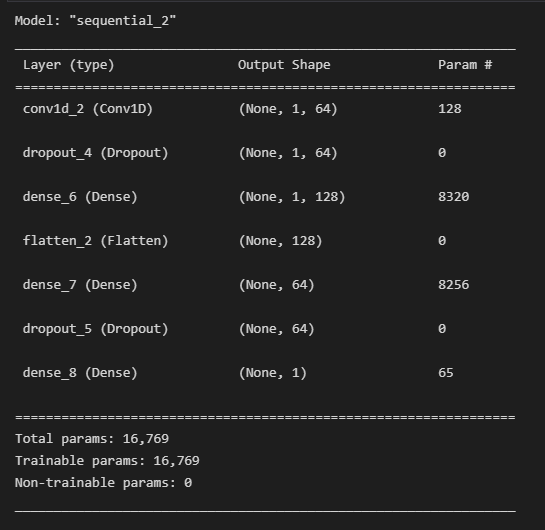
7. 모델 컴파일
model.compile(loss='mse',optimizer='adam',metrics="accuracy")
early_stop = EarlyStopping(monitor='val_loss', patience=100)
model.fit(x_train,y_train,validation_data=(x_valid, y_valid), callbacks=[early_stop],epochs=1000,batch_size=100)8. 시각화로 비교해보기.
import matplotlib.pyplot as plt
pred=model.predict(test_feature)
plt.figure(figsize=(12, 9))
plt.plot(test_label, label = 'actual')
plt.plot(pred, label = 'prediction')
plt.legend()
plt.show()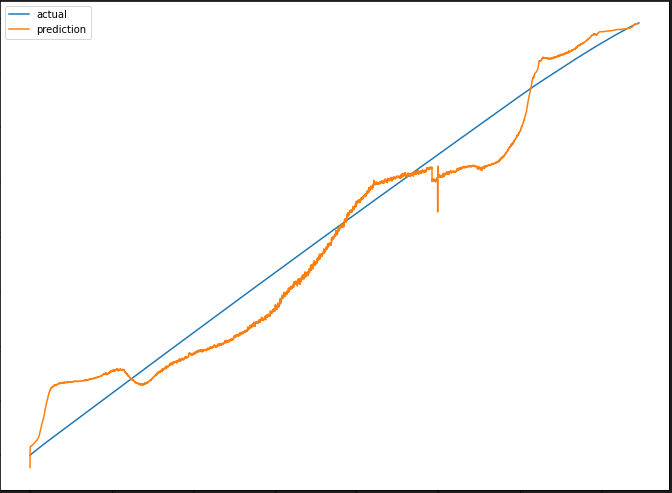
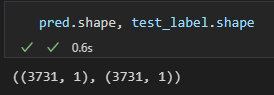
마지막으로 비교한 두가지의 크기를 확인해보면 아래와 같다.
'인공지능 (Deep Learning) > 딥러닝 사이드 Project' 카테고리의 다른 글
| [트랜스포머] 트랜스포머 인코더를 이용한 시계열 예측. (2) | 2023.07.13 |
|---|---|
| [CNN-Tensorflow] 커스텀 데이터 활용 이미지 분류 예제 코드 설명 (5) | 2023.02.26 |
| YOLOv5 커스텀 데이터셋으로 학습하기 (27) | 2022.11.04 |
| [CNN] Conv1D 커널(필터) 작동 방식 설명 (시계열 데이터 비교) (0) | 2022.09.02 |
| [LSTM] 예제 코드 설명 (시계열 데이터 예측) (0) | 2022.08.20 |



