● DFS (Depth-First-Search)
: 최대한 깊이 내려간뒤, 더이상 깊이 갈 곳이 없을 경우 옆으로 이동
깊이 우선 탐색 알고리즘 이라고도 한다. 단어 그대로 깊은 부분(가장 멀리 있는 노드)을 우선적으로
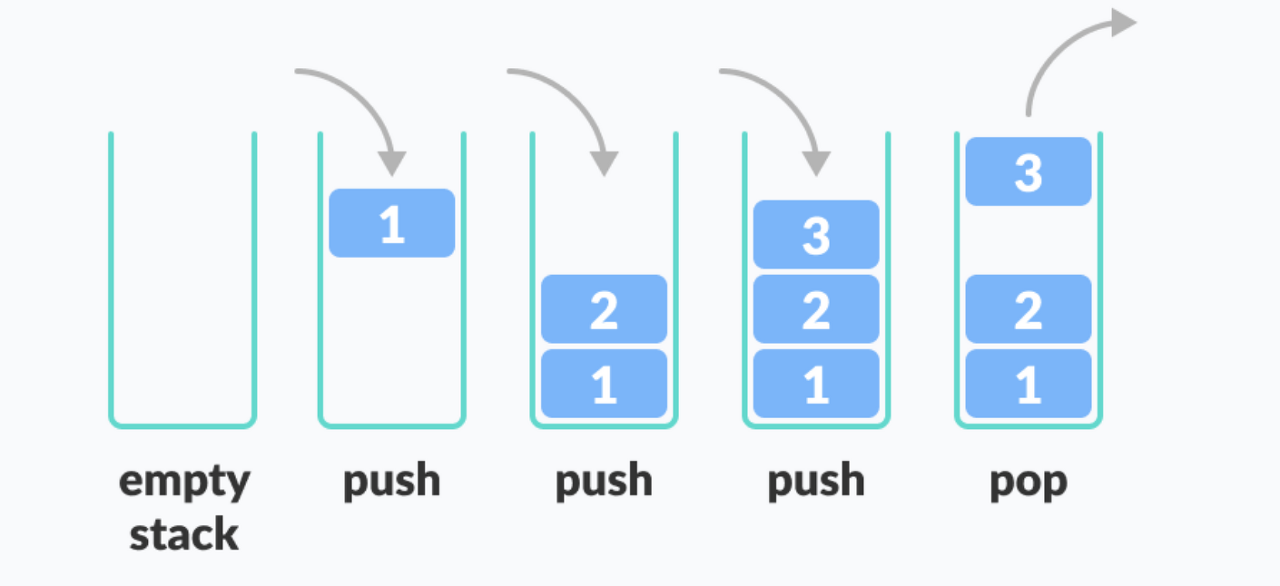
탐색한다는 알고리즘이다. DFS 는 스택이라는 자료구조를 활용해서 구현이 되며.
스택자료구조는 FILO(First-in-Last-Out) 방식을 따른다.
<DFS 알고리즘>

<스택 자료구조>
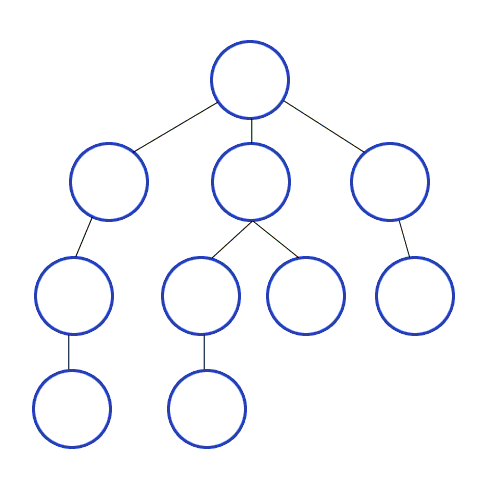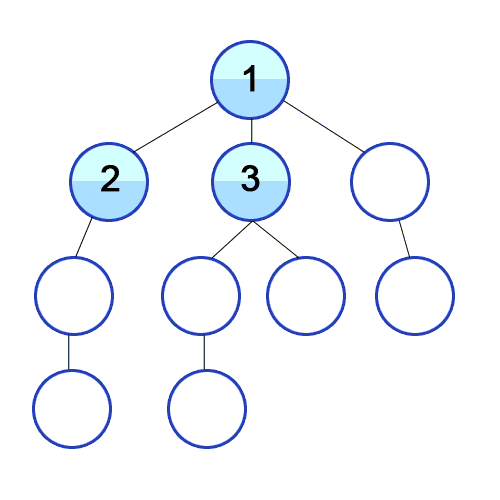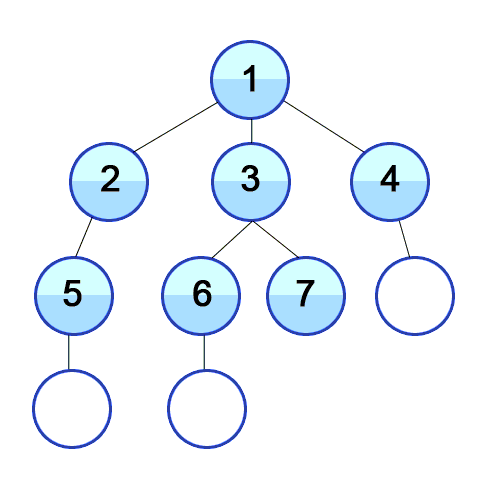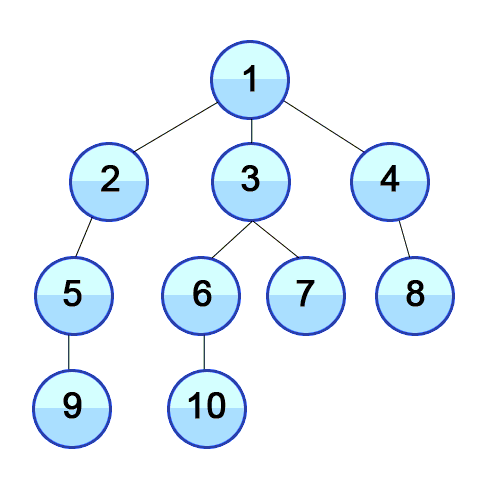
<주어진 그래프>

# 각 노드가 연결된 정보를 리스트 자료형으로 표현(2차원 리스트)
graph=[
[],
[2,3,8], # 1번 노드는 2,3,8,노드랑 연결되있음
[1,7], # 2번 노드는 1,7 번 노드랑 연결되있음
[1,4,5],
[3,5],
[3,4],
[7],
[2,6,8],
[1,7]
]
#각 노드가 방문된 정보를 리스트 자료형으로 표현(1차원 리스트)
visited=[False]*9 # 방문하지 않은 노드=False, 방문한 노드=True
# dfs라는 함수 호출
dfs(graph,1,visited) # 0번 노드가 없으니 1번 노드 부터 호출함
#dfs 함수 구현
def dfs(graph,v,visited): # 깊이우선탐색 _ 재귀 함수 이용, 스택을 이용
visited[v]=True
print(v,end=' ')
for i in graph[v]: # grpah에 있는 노드 찾음
if not visited[i]: # visited[i] 가 False 일경우에 실행
dfs(graph,i,visited) # graph 와 visited 는 계속 유지 되어야함
# (그래야 이전 정보가 게속 연결되니깐)
# 재귀함수를 통해 깊은곳으로 탐색해 들어감
#출력 값
1 2 3 8 7 4 5 6
● BFS (Breadth-First-Search)
: 최대한 넓게 이동한 다음, 더 이상 갈 수 없을 때 아래로 이동
너비 우선 탐색 알고리즘 이라고도 한다. 너비 우선 탐색은 가장 가까운 노트부터 탐색하는
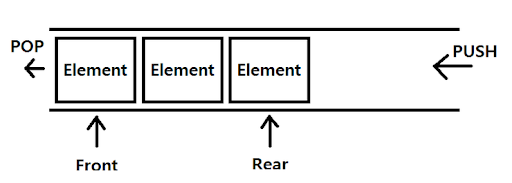
알고리즘이다. BFS는 큐라는 자료구조를 사용한다. 큐는 FIFO(First-In-First-Out)방식을
사용한다.
<BFS 알고리즘>
<큐 자료구조>
# ' collections ' =라이브러리, 'deque' = 메서드
from collections import deque
# 각 노드가 연결된 정보를 리스트 자료형으로 표현(2차원 리스트)
graph=[
[],
[2,3,8], # 1번 노드는 2,3,8,노드랑 연결되있음
[1,7], # 2번 노드는 1,7 번 노드랑 연결되있음
[1,4,5],
[3,5],
[3,4],
[7],
[2,6,8],
[1,7]
]
#각 노드가 방문된 정보를 리스트 자료형으로 표현(1차원 리스트)
visited=[False]*9 # 방문하지 않은 노드=False, 방문한 노드=True
# bfs라는 함수 호출
bfs(graph,1,visited) # 0번 노드가 없으니 1번 노드 부터 호출함
#bfs 함수 구현
def bfs(graph, start, visited): # 너비 우선 탐색
queue = deque([start]) # 시작 노드를 큐에다가 먼저 삽입(삽입할 때 파이썬 리스트[]로 감싸주기)
visited[start] = True # 시작 노드를 방문 처리
# 큐에서 노드를 pop하고 그 노드의 인접노드들을 탐색. 단, 큐가 빌(False)때 까지// []가 false임
while queue: # 빈 리스트가 될때까지 반복함
v = queue.popleft()
print(v, end=' ')
for i in graph[v]: # 인접한노드(가까운노드)부터 탐색
if not visited[i]:
visited[i] = True
queue.append(i)
#출력 값
1 2 7 6 8 3 4 5
● 특징
| DFS (깊이우선 탐색) | BFS (너비 우선 탐색) |
| 현재 정점에서 갈 수 있는 점들까지 들어가면서 탐색 | 현재 정점에 연결된 가까운 점들부터 탐색 |
| 스택 또는 재귀함수로 구현 | 큐를 이용해서 구현 |
● DFS,BFS 특징에 따라 사용에 더 적합한 문제 유형
- 그래프의 모든 정점을 방문하는 것이 주요한 문제
단순히 모든 정점을 방문하는 것이 중요한 문제의 경우 DFS, BFS 두 가지 방법 중 어느 것을 사용하셔도 상관없습니다.
둘 중 편한 것을 사용하시면 됩니다. - 경로의 특징을 저장해둬야 하는 문제
예를 들면 각 정점에 숫자가 적혀있고 a부터 b까지 가는 경로를 구하는데 경로에 같은 숫자가 있으면 안 된다는 문제 등, 각각의 경로마다 특징을 저장해둬야 할 때는 DFS를 사용합니다. (BFS는 경로의 특징을 가지지 못합니다) - 최단거리 구해야 하는 문제
미로 찾기 등 최단거리를 구해야 할 경우, BFS가 유리합니다.
왜냐하면 깊이 우선 탐색으로 경로를 검색할 경우 처음으로 발견되는 해답이 최단거리가 아닐 수 있지만,
너비 우선 탐색으로 현재 노드에서 가까운 곳부터 찾기 때문에경로를 탐색 시 먼저 찾아지는 해답이 곧 최단거리기 때문입니다.
이밖에도
- 검색 대상 그래프가 정말 크다면 DFS를 고려
- 검색대상의 규모가 크지 않고, 검색 시작 지점으로부터 원하는 대상이 별로 멀지 않다면 BFS
( DFS,BFS 특징에 따라 사용에 더 적합한 문제 유형 출처:
https://velog.io/@lucky-korma/DFS-BFS%EC%9D%98-%EC%84%A4%EB%AA%85-%EC%B0%A8%EC%9D%B4%EC%A0%90 )
'새롭게 알게된_tech > 파이썬_tech' 카테고리의 다른 글
| 10. 숫자를 리스트(문자열,숫자) 로 변환하기 (0) | 2022.01.30 |
|---|---|
| 9. list() 함수 (1) | 2022.01.27 |
| 7. 출력문 print(sep='' , end='') (0) | 2022.01.26 |
| 6. 파이썬의 참 및 거짓 값 (0) | 2022.01.26 |
| 5. 2차원 리스트 제거하기 (0) | 2022.01.25 |

