글의 목적 : 한참 쓸때는 잘 알다가 잠깐 안쓰니깐 햇갈려서, 햇갈리는 차이(?)만 그림으로 정리했다.
1. Seq2Seq
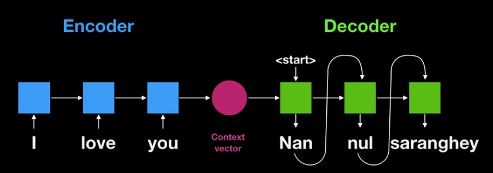
아래의 그림이 끝이다.
1. 각각의 파랑색 cell(STM , RNN 등)들이 흘러흘러~~ 가서 마지막 셀에서 Context vector를 뽑아낸다.
2. 즉, Context vector 는 마지막 cell의 Hidden state이다.
단점 :
1. Context vector는 고정된 사이즈 임으로, 모든 정보를 압축하지 못하는 한계 존재
2. RNN, LSTM의 근본적인 한계점인 '장기 의존성 문제' 문제 발생
2. Attention Mechanism
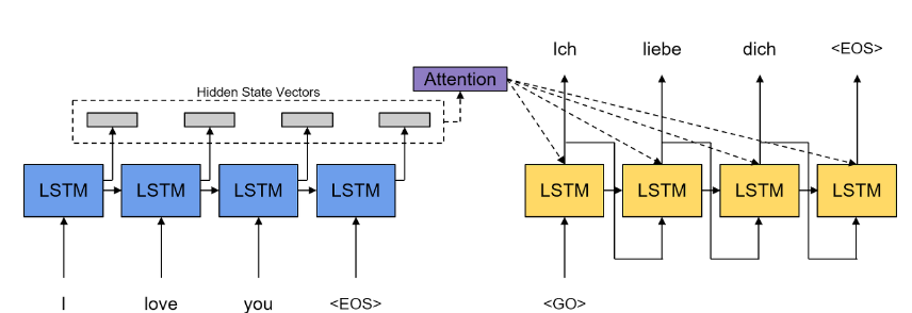
아래와 같이 2개의 그림으로 보면 이해가 편하다.
-> Seq2Seq 와는 다르게 각각의 셀에서 나온 모든 Hidden state를 활용함, Decoder 에서는 모든 Hidden state중에서 필요한 부분에 집중해서 attention(집중)활용함.
단점 :
1. RNN, LSTM의 구조를 활용하고 있기에, RNN과 LSTM의 한계를 벗어나지못함.(장기 의존성 문제 존재)
2. 병렬적 처리 문제, 장기 의존성 문제 여전히 존재 입력 시퀀스에 대해서 순서에 대한 정보가 사라져있음.



3. Transformer : Self attention
같은 입력 시퀀스로부터 Query 와 Key 벡터들 간의 Scaled dot prodcut(내적) 를 통해, 각 Query가 전체 Key 중 어디에 주목할지(attention weight)를 계산한다.
1. Query는 전체 Key들과 각각 내적을 수행하여 모든 Key에 대한 유사도를 구하고, 이를 기반으로 어떤 Key에 어느 정도 집중할지를 정한다.
2. 계산된 유사도(내적)는 softmax 함수를 통해 정규화된 attention weight가 되고, 이 weight를 각 Value에 곱해 가중합(weighted sum)을 수행한다.
3. 이 과정을 통해 각 Query는 전체 입력 시퀀스 중에서 어떤 시점(Key)에 주목해야 하는지를 학습하게 되며, 그 결과로 문맥을 반영한 새로운 표현(Context Vector)이 생성된다.
'인공지능 (Deep Learning) > 딥러닝 및 파이토치 기타 정리' 카테고리의 다른 글
| [Multi GPU] MultiGPU를 통한 학습 (2) | 2024.08.27 |
|---|---|
| [LoRA] Low-Rank Adaptation of Large Language models (0) | 2024.08.22 |
| [import os] 파일 호출, 삭제, 생성 명령어. (0) | 2024.05.26 |
| [Pytorch, Huggingface] Pretrained Model 의 특정 Layer 만 Freeze 하기 (1) | 2024.04.28 |
| [Pytorch, Huggingface] Pretrained Model 의 특정 Layer 만 추출 (1) | 2024.04.26 |


