► wandb 사용 목적 : 모델 (하이퍼)파라미터 최적화 용도 = MLOps
► 본 글에서 사용 목적 : Transformer 모델의 Attention head와 Encoder block 수에 따른 최적화를 찾기 위한 용도
공식 docs: https://docs.wandb.ai/guides/sweeps/sweep-config-keys
(여기에 들어가면 더 필요한 세부적인 파라미터를 확인 할 수 있음)
✓ 아래의 사진은 Sweep 를 위한 기본적인 옵션이다.
- Sweep : 하이퍼 파라미터를 최적화하는 도구

→ 위의 파라미터를 보면 required와 아닌것으로 구분할 수 있다.
- method : 아래 3가지를 지원한다. 각각의 정의와 필요한것을 선택하는 기준은 타 블로그에서 개념을 찾아보면 좋을듯하다.
- grid, random, bayes
- metric : 평가 메트릭스(지표).
- name : 최적화 하기 위한 metric 이름
- goal : task에 맞게 설정하면됨. (minimize, maximize)
- parameters : 최적화 실험에 사용하고 싶은 파라미터
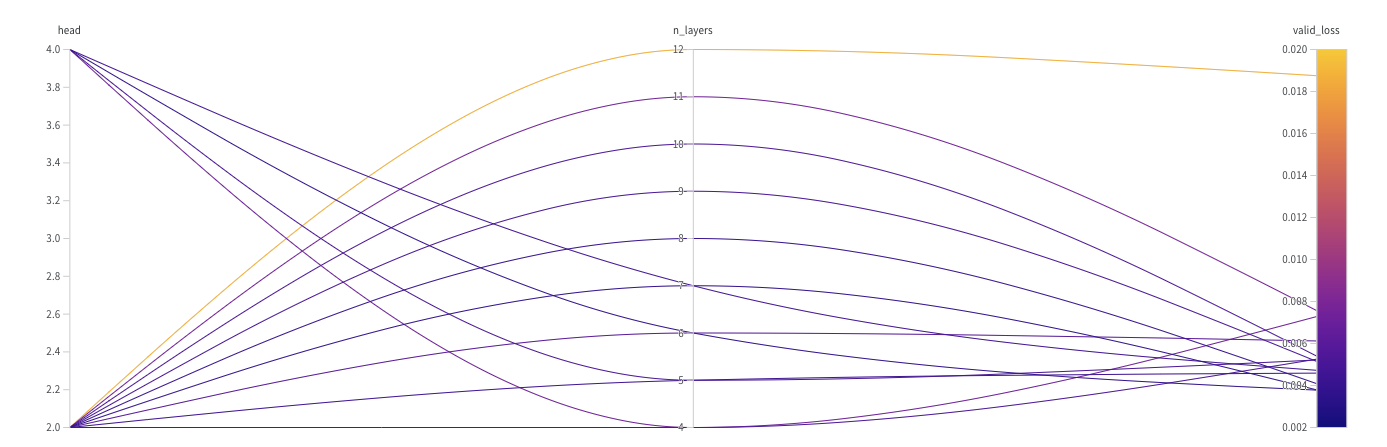
- head ( 글쓴이가 실험에 필요한 파라미터) : attention head 수 , [2, 4, 8, 16] 으로 4개중에 선택하며 실험 진행함.
- n_layers ( 글쓴이가 실험에 필요한 파라미터) : encoder block 수 , [4~12] 범위 안에 값을 모두 돌아가며 실험 진행함.
- early_terminate : 조기종료조건 (성능이 좋지 않은것에 대해 현재 실행을 중지함.)
- type : hyperband (https://arxiv.org/abs/1603.06560)
논문을 읽어봐야 할듯.. - min_iter : 최소 몇 번의 epcoh를 실행 후 평가할 것인지
- max_iter : 최대 몇 번까지 실행할 것인지
- s : hyperband의 reduction factor (성능이 나쁜 실험을 종료하는 기준을 정하는 값)
- type : hyperband (https://arxiv.org/abs/1603.06560)
(아래와 같이 나는 yaml파일을 이용하여 파라미터를 정의하고 활용하였다. 여기서 program 의 인자값을 설정하지 않은것을 확인할 수 있다. 하지만 .py파일에서 아래의 코드를 사용하면 yaml파일을 불러서 사용할 수 있다. )

# YAML 파일을 로드하여 sweep config로 사용
with open("sweep_config.yaml") as file:
sweep_config = yaml.safe_load(file)
✓ 이제 코드에 적용하는 방법을 찾아보자.
( 코드적용에 핵심적인 내용만 작성함)
- Sweep 생성
- wandb 초기화 → config값을 실험하려는 파라미터에 부여.
- wandb.agent 선언
import wandb
import yaml
# YAML 파일을 로드하여 sweep config로 사용
with open("sweep_config.yaml") as file:
sweep_config = yaml.safe_load(file)
# Sweep 생성
sweep_id = wandb.sweep(sweep_config, project="transformer_241106_ver2")
def train():
# Initialize W&B and set up the configuration
wandb.init()
config = wandb.config
CNN_transformer = Encoder(
input_size=3,
num_predicted_features=1,
d_model=128,
head=config.head, # yaml파일에서 보았던 파라미터 인자값으로 conifg 함.
d_ff=32,
max_len=144,
dropout=0.2,
n_layers=config.n_layers # yaml파일에서 보았던 파라미터 인자값으로 conifg 함.
).to(device)
train_losses = []
valid_losses = []
avg_train_losses = []
avg_valid_losses = []
# 학습코드
for epoch in range(nb_epochs):
CNN_transformer.train()
for batch_idx, samples in enumerate(train_dataloader):
x_train, y_train = samples
x_train, y_train = x_train.to(device), y_train.to(device)
prediction = CNN_transformer(x_train)
loss = F.l1_loss(prediction, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_losses.append(loss.item())
# validation으로 매 epoch 마다 성능 확인.
CNN_transformer.eval()
with torch.no_grad():
for batch_idx, samples in enumerate(val_dataloader):
x_val, y_val = samples
x_val, y_val = x_val.to(device), y_val.to(device)
prediction = CNN_transformer(x_val)
loss = F.l1_loss(prediction, y_val)
valid_losses.append(loss.item())
train_loss = np.average(train_losses)
valid_loss = np.average(valid_losses)
avg_train_losses.append(train_loss)
avg_valid_losses.append(valid_loss)
wandb.log({"epoch": epoch + 1, "train_loss": train_loss, "valid_loss": valid_loss})
train_losses = []
valid_losses = []
wandb.agent(sweep_id, function=train)✓ 실험이 진행중이라면 아래와 같은 UI 가 나옴.
(실험이 오래걸리네...)
'인공지능 (Deep Learning) > 딥러닝 스크래치 코드' 카테고리의 다른 글
| [Pytorch 스크래치 코드] Evaluation 코드 (0) | 2023.12.28 |
|---|---|
| [Pytorch 스크래치 코드] 회귀문제 Train, Validation 함수 (1) | 2023.12.17 |
| [Pytorch 스크래치 코드] 분류문제 Train, Validation 함수 (0) | 2023.12.16 |
| [Pytorch 스크래치 코드] Train Test split (1) | 2023.12.10 |
| [Pytorch 스크래치 코드] 실험 재현을 위한 Seed 고정 (0) | 2023.12.09 |



